原文地址:https://ddnd.cn/2019/03/10/jdk1-8-concurrenthashmap/
前言
ConcurrentHashMap顾名思义就是同步的HashMap,也就是线程安全的HashMap,所以本篇介绍的ConcurrentHashMap和HashMap有着很重要的关系,所以建议之前没有了解过HashMap的可以先看看这篇关于HashMap的原理分析《HashMap从认识到源码分析》,本篇继续以JDK1.8版本的源码进行分析,最后在介绍完ConcurrentHashMap之后会对ConcurrentHashMap、Hashtable和HashMap做一个比较和总结。
ConcurrentHashMap
我们先看一下ConcurrentHashMap实现了哪些接口、继承了哪些类,对ConcurrentHashMap有一个整体认知。
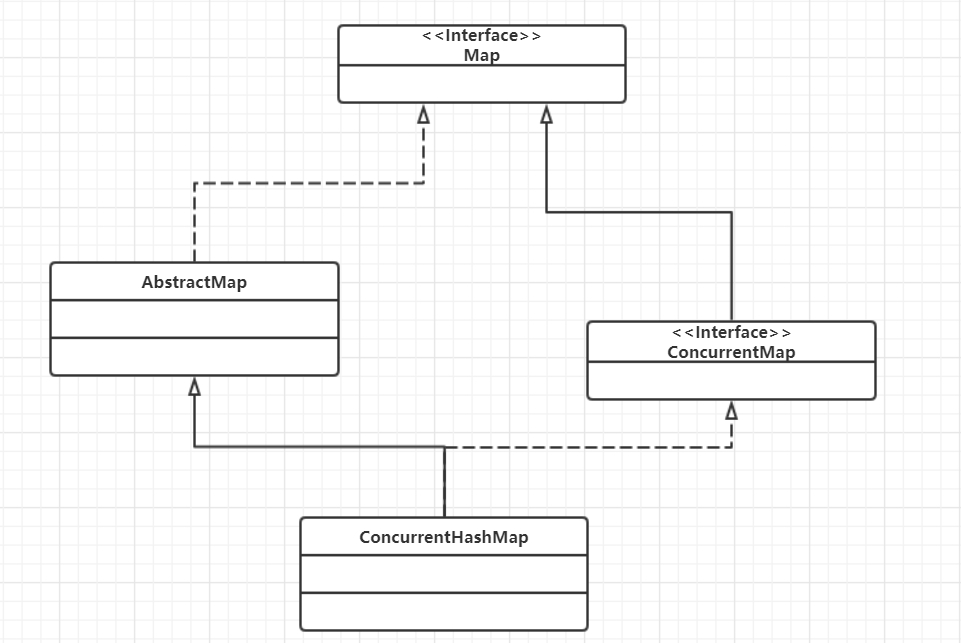
ConcurrentHashMap继承AbstractMap接口,这个和HashMap一样,然后实现了ConcurrentMap接口,这个和HashMap不一样,HashMap是直接实现的Map`接口。
再细看ConcurrentHashMap的结构,这里列举几个重要的成员变量table、nextTable、baseCount、sizeCtl、transferIndex、cellsBusy
table:数据类型是Node数组,这里的Node和HashMap的Node一样都是内部类且实现了
Map.Entry接口nextTable:哈希表扩容时生成的数据,数组为扩容前的2倍
sizeCtl :多个线程的共享变量,是操作的控制标识符,它的作用不仅包括
threshold的作用,在不同的地方有不同的值也有不同的用途:-1代表正在初始化-N代表有N-1个线程正在进行扩容操作0代表hash表还没有被初始化- 正数表示下一次进行扩容的容量大小
ForwardingNode:一个特殊的Node节点,Hash地址为-1,存储着nextTable的引用,只有table发生扩用的时候,ForwardingNode才会发挥作用,作为一个占位符放在table中表示当前节点为null或者已被移动
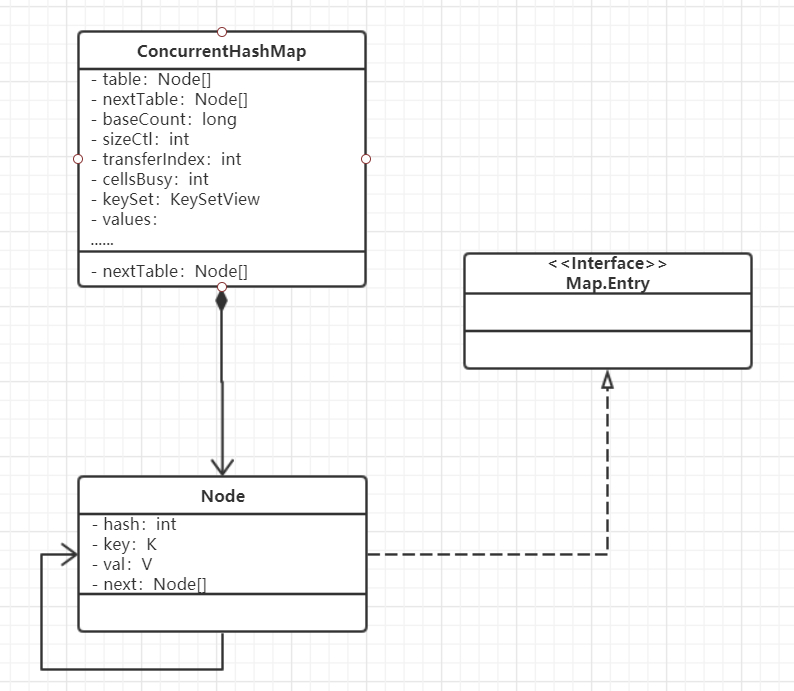
ConcurrentHashMap和HashMap一样都是采用拉链法处理哈希冲突,且都为了防止单链表过长影响查询效率,所以当链表长度超过某一个值时候将用红黑树代替链表进行存储,采用了数组+链表+红黑树的结构
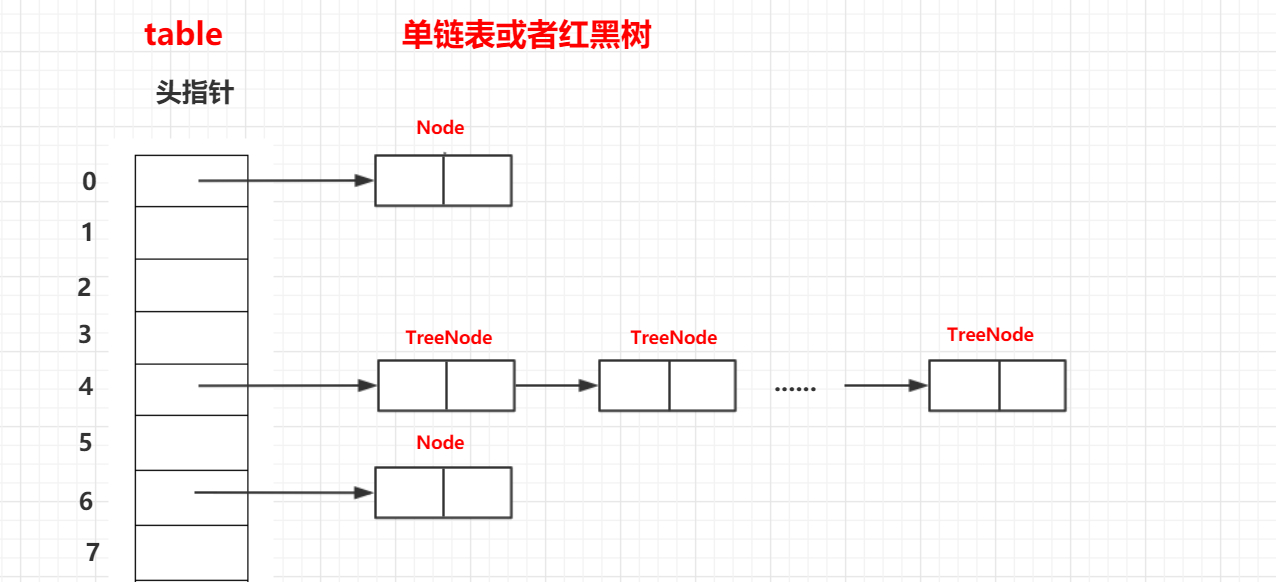
所以从结构上看HashMap和ConcurrentHashMap还是很相似的,只是ConcurrentHashMap在某些操作上采用了CAS + synchronized来保证并发情况下的安全。
说到ConcurrentHashMap处理并发情况下的线程安全问题,这不得不提到Hashtable,因为Hashtable也是线程安全的,那ConcurrentHashMap和Hashtable有什么区别或者有什么高明之处嘛?以至于官方都推荐使用ConcurrentHashMap来代替Hashtable
线程安全的实现:
Hashtable采用对象锁(synchronized修饰对象方法)来保证线程安全,也就是一个Hashtable对象只有一把锁,如果线程1拿了对象A的锁进行有synchronized修饰的put方法,其他线程是无法操作对象A中有synchronized修饰的方法的(如get方法、remove方法等),竞争激烈所以效率低下。而ConcurrentHashMap采用CAS+synchronized来保证并发安全性,且synchronized关键字不是用在方法上而是用在了具体的对象上,实现了更小粒度的锁,等会源码分析的时候在细说这个SUN大师们的鬼斧神工数据结构的实现:
Hashtable采用的是数组 + 链表,当链表过长会影响查询效率,而ConcurrentHashMap采用数组 + 链表 + 红黑树,当链表长度超过某一个值,则将链表转成红黑树,提高查询效率。
构造函数
ConcurrentHashMap的构造函数有5个,从数量上看就和HashMap、Hashtable(4个)的不同,多出的那个构造函数是public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel),即除了传入容量大小、负载因子之外还多传入了一个整型的concurrencyLevel,这个整型是我们预先估计的并发量,比如我们估计并发是30,那么就可以传入30。
其他的4个构造函数的参数和HashMap的一样,而具体的初始化过程却又不相同,HashMap和Hashtable传入的容量大小和负载因子都是为了计算出初始阈值(threshold),而ConcurrentHashMap传入的容量大小和负载因子是为了计算出sizeCtl用于初始化table,这个sizeCtl即table数组的大小,不同的构造函数计算sizeCtl方法都不一样。
1 | //无参构造函数,什么也不做,table的初始化放在了第一次插入数据时,默认容量大小是16和HashMap的一样,默认sizeCtl为0 |
put方法
- 判断键值是否为
null,为null抛出异常。 - 调用
spread()方法计算key的hashCode()获得哈希地址,这个HashMap相似。 - 如果当前table为空,则初始化table,需要注意的是这里并没有加
synchronized,也就是允许多个线程去尝试初始化table,但是在初始化函数里面使用了CAS保证只有一个线程去执行初始化过程。 - 使用 容量大小-1 & 哈希地址 计算出待插入键值的下标,如果该下标上的bucket为
null,则直接调用实现CAS原子性操作的casTabAt()方法将节点插入到table中,如果插入成功则完成put操作,结束返回。插入失败(被别的线程抢先插入了)则继续往下执行。 - 如果该下标上的节点(头节点)的哈希地址为-1,代表需要扩容,该线程执行
helpTransfer()方法协助扩容。 - 如果该下标上的bucket不为空,且又不需要扩容,则进入到bucket中,同时锁住这个bucket,注意只是锁住该下标上的bucket而已,其他的bucket并未加锁,其他线程仍然可以操作其他未上锁的bucket,这个就是ConcurrentHashMap为什么高效的原因之一。
- 进入到bucket里面,首先判断这个bucket存储的是红黑树(哈希地址小于0,原因后面分析)还是链表。
- 如果是链表,则遍历链表看看是否有哈希地址和键key相同的节点,有的话则根据传入的参数进行覆盖或者不覆盖,没有找到相同的节点的话则将新增的节点插入到链表尾部。如果是红黑树,则将节点插入。到这里结束加锁。
- 最后判断该bucket上的链表长度是否大于链表转红黑树的阈值(8),大于则调用
treeifyBin()方法将链表转成红黑树,以免链表过长影响效率。 - 调用
addCount()方法,作用是将ConcurrentHashMap的键值对数量+1,还有另一个作用是检查ConcurrentHashMap是否需要扩容。
1 | public V put(K key, V value) { |
get方法
- 调用
spread()方法计算key的hashCode()获得哈希地址。 - 计算出键key所在的下标,算法是(n - 1) & h,如果table不为空,且下标上的bucket不为空,则到bucket中查找。
- 如果bucket的头节点的哈希地址小于0,则代表这个bucket存储的是红黑树,否则是链表。
- 到红黑树或者链表中查找,找到则返回该键key的值,找不到则返回null。
1 | public V get(Object key) { |
remove方法
- 调用
spread()方法计算出键key的哈希地址。 - 计算出键key所在的数组下标,如果table为空或者bucket为空,则返回
null。 - 判断当前table是否正在扩容,如果在扩容则调用helpTransfer方法协助扩容。
- 如果table和bucket都不为空,table也不处于在扩容状态,则锁住当前bucket,对bucket进行操作。
- 根据bucket的头结点判断bucket是链表还是红黑树。
- 在链表或者红黑树中移除哈希地址、键key相同的节点。
- 调用
addCount方法,将当前table存储的键值对数量-1。
1 | public V remove(Object key) { |
initTable初始化方法
table的初始化主要由initTable()方法实现的,initTable()方法初始化一个合适大小的数组,然后设置sizeCtl。 我们知道ConcurrentHashMap是线程安全的,即支持多线程的,那么一开始很多个线程同时执行put()方法,而table又没初始化,那么就会很多个线程会去执行initTable()方法尝试初始化table,而put方法和initTable方法都是没有加锁的(synchronize),那SUN的大师们是怎么保证线程安全的呢?
通过源码可以看得出,table的初始化只能由一个线程完成,但是每个线程都可以争抢去初始化table。
- 判断table是否为
null,即需不需要首次初始化,如果某个线程进到这个方法后,其他线程已经将table初始化好了,那么该线程结束该方法返回。 - 如果table为
null,进入到while循环,如果sizeCtl小于0(其他线程正在对table初始化),那么该线程调用Thread.yield()挂起该线程,让出CPU时间,该线程也从运行态转成就绪态,等该线程从就绪态转成运行态的时候,别的线程已经table初始化好了,那么该线程结束while循环,结束初始化方法返回。如果从就绪态转成运行态后,table仍然为null,则继续while循环。 - 如果table为
null且sizeCtl不小于0,则调用实现CAS原子性操作的compareAndSwap()方法将sizeCtl设置成-1,告诉别的线程我正在初始化table,这样别的线程无法对table进行初始化。如果设置成功,则再次判断table是否为空,不为空则初始化table,容量大小为默认的容量大小(16),或者为sizeCtl。其中sizeCtl的初始化是在构造函数中进行的,sizeCtl = ((传入的容量大小 + 传入的容量大小无符号右移1位 + 1)的结果向上取最近的2幂次方)
1 | private final Node<K,V>[] initTable() { |
transfer扩容方法
transfer()方法为ConcurrentHashMap扩容操作的核心方法。由于ConcurrentHashMap支持多线程扩容,而且也没有进行加锁,所以实现会变得有点儿复杂。整个扩容操作分为两步:
- 构建一个nextTable,其大小为原来大小的两倍,这个步骤是在单线程环境下完成的
- 将原来table里面的内容复制到nextTable中,这个步骤是允许多线程操作的,所以性能得到提升,减少了扩容的时间消耗。
1 | //协助扩容方法 |
addCount、sumCount方法
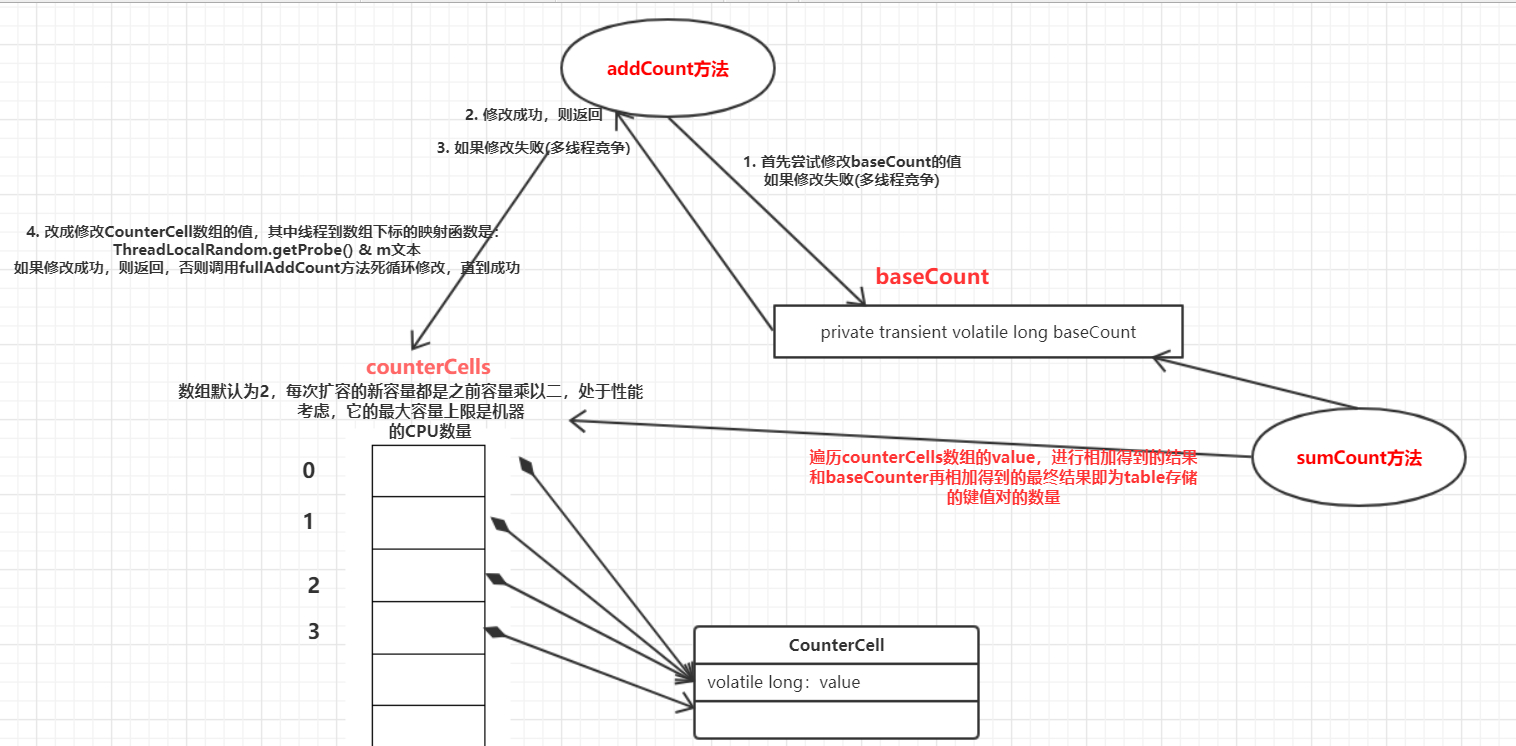
addCount()做的工作是更新table的size,也就是table存储的键值对数量,在使用put()和remove()方法的时候都会在执行成功之后调用addCount()来更新table的size。对于ConcurrentHashMap来说,它到底有储存有多少个键值对,谁也不知道,因为他是支持并发的,储存的数量无时无刻都在变化着,所以说ConcurrentHashMap也只是统计一个大概的值,为了统计出这个值也是大费周章才统计出来的。
1 | private final void addCount(long x, int check) { |
size、mappingCount方法
size和mappingCount方法都是用来统计table的size的,这两者不同的地方在size返回的是一个int类型,即可以表示size的范围是[-2^31,2^31-1],超过这个范围就返回int能表示的最大值,mappingCount返回的是一个long类型,即可以表示size的范围是[-2^63,2^63-1]。
这两个方法都是调用的sumCount()方法实现统计。
1 | public int size() { |
HashMap、Hashtable、ConcurrentHashMap三者对比
| \ | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| 是否线程安全 | 否 | 是 | 是 |
| 线程安全采用的方式 | 采用synchronized类锁,效率低 |
采用CAS + synchronized,锁住的只有当前操作的bucket,不影响其他线程对其他bucket的操作,效率高 |
|
| 数据结构 | 数组+链表+红黑树(链表长度超过8则转红黑树) | 数组+链表 | 数组+链表+红黑树(链表长度超过8则转红黑树) |
是否允许null键值 |
是 | 否 | 否 |
| 哈希地址算法 | (key的hashCode)^(key的hashCode无符号右移16位) | key的hashCode | ( (key的hashCode)^(key的hashCode无符号右移16位) )&0x7fffffff |
| 定位算法 | 哈希地址&(容量大小-1) | (哈希地址&0x7fffffff)%容量大小 | 哈希地址&(容量大小-1) |
| 扩容算法 | 当键值对数量大于阈值,则容量扩容到原来的2倍 | 当键值对数量大于等于阈值,则容量扩容到原来的2倍+1 | 当键值对数量大于等于sizeCtl,单线程创建新哈希表,多线程复制bucket到新哈希表,容量扩容到原来的2倍 |
| 链表插入 | 将新节点插入到链表尾部 | 将新节点插入到链表头部 | 将新节点插入到链表尾部 |
| 继承的类 | 继承abstractMap抽象类 |
继承Dictionary抽象类 |
继承abstractMap抽象类 |
| 实现的接口 | 实现Map接口 |
实现Map接口 |
实现ConcurrentMap接口 |
| 默认容量大小 | 16 | 11 | 16 |
| 默认负载因子 | 0.75 | 0.75 | 0.75 |
| 统计size方式 | 直接返回成员变量size |
直接返回成员变量count |
遍历CounterCell数组的值进行累加,最后加上baseCount的值即为size |
参考
【死磕Java并发】—–J.U.C之Java并发容器:ConcurrentHashMap
Map 大家族的那点事儿 ( 7 ) :ConcurrentHashMap
Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
Java 8 ConcurrentHashMap源码分析